

Multi-Scale Correlated iAFF-Res2Net Voiceprint Recognition Model
-
摘要:
为解决当前声纹识别领域中在噪声环境下特征融合方法难以同时捕捉局部和全局特征的问题,提出一种改进的网络架构iAFF-Res2Net. 首先,该架构以轻量级网络Res2Net为基础,引入集成了多尺度通道注意力的注意力特征融合(AFF)模块,以强化特征处理能力;其次,为减小初始特征输入权重带来的影响,引入迭代注意力特征融合(iAFF)机制,进一步细化特征的权重分布;此外,在生成固定特征嵌入时,采用结合了全局上下文注意力机制的注意力统计池化(ASTP)替代传统的平均池化,以增强帧级特征的聚合能力;最后,通过优化附加角度边距损失函数(ArcMarginLoss)实现说话人身份认证. 在VoxCeleb数据集上的实验结果表明:iAFF-Res2Net模型的等错误率(EER)和最小检测成本函数(min DCF)分别达到了0.60%、 0.053,均低于ResNet34、ResNet50、Res2Net、ECAPA-TDNN经典模型,且改进后的模型具有更优的收敛速度和特征判别能力.
Abstract:An improved network architecture named iAFF-Res2Net was proposed to address the problem of capturing both local and global features effectively in feature fusion under noisy conditions for voiceprint recognition. Firstly, a lightweight Res2Net was adopted as the backbone, and an Attention Feature Fusion (AFF) module with multi-scale channel attention was integrated to enhance feature representation. Secondly, an Iterative Attention Feature Fusion (iAFF) mechanism was introduced to reduce the bias caused by initial feature weighting, thereby refining feature weight distributions. Furthermore, during the generation of fixed speaker embeddings, traditional average pooling was replaced by Attentive Statistics Pooling (ASTP) with global context attention to improve frame-level feature aggregation. Finally, Angular Additive Margin Softmax (ArcMarginLoss) was used for speaker verification. Experimental results on the VoxCeleb dataset show that the iAFF-Res2Net models achieve equal error rates (EER) of 0.60%, and minimum detection cost functions (MinDCF) of 0.053. Both models outperform classical architectures such as ResNet34, ResNet50, Res2Net, and ECAPA-TDNN. Moreover, the improved models exhibit faster convergence and stronger feature discriminability.
-
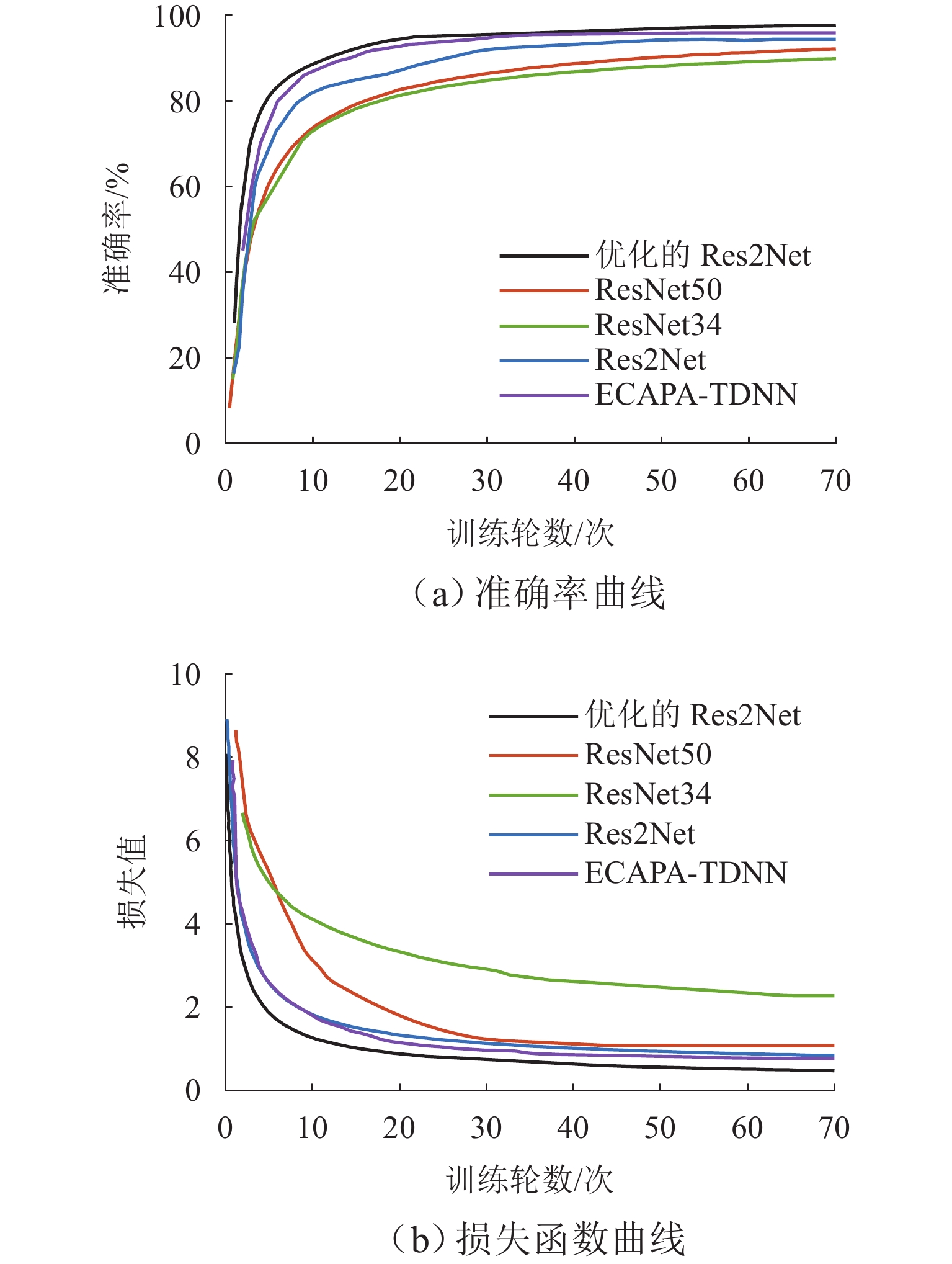
图 7不同模型的准确率和损失函数曲线
Figure 7.Accuracy curves and loss function curves of different models

图 8iAFF-Res2Net与AFF-Res2Net准确率和损失函数曲线
Figure 8.Accuracy curves and loss function curves of iAFF-Res2Net and AFF-Res2Net
表 1不同模型的参数量及性能指标
Table 1.The number of parameters and performance metrics of different networks
模型 参数量/M EER/% min DCF ResNet34 23.3 2.63 0.317 ResNet50 21.4 2.24 0.299 Res2Net 5.63 1.50 0.138 ECAPA-TDNN 20.8 0.91 0.116 优化的 Res2Net 8.61 0.89 0.087  下载:
导出CSV
下载:
导出CSV
表 2不同特征融合模块对AFF-Res2Net性能的影响
Table 2.Impact of different feature fusion modules on AFF-Res2Net performance
模型 EER/% min DCF Res2Net 1.50 0.138 Res2Net + 局部特征融合 0.89 0.087 Res2Net + 全局特征融合 1.18 0.124 AFF-Res2Net 0.76 0.085 下载:
导出CSV
表 3不同池化策略在AFF-Res2Net模型中的性能表现
Table 3.Performance of different pooling strategies in the AFF-Res2Net model
模型 池化策略 EER/% min DCF AFF-Res2Net 平均池化 0.81 0.088 AFF-Res2Net 最大池化 0.80 0.087 AFF-Res2Net ASTP 0.76 0.085 下载:
导出CSV
表 4iAFF-Res2Net与AFF-Res2Net性能比较
Table 4.Performance comparison between iAFF-Res2Net and AFF-Res2Net
模型 EER/% min DCF AFF-Res2Net 0.76 0.085 iAFF-Res2Net 0.60 0.053 下载:
导出CSV
-
[1] 李平, 高清源, 夏宇, 等. 基于SE-DR-Res2Block的声纹识别方法[J]. 工程科学学报, 2023, 45(11): 1962-1969.LI Ping, GAO Qingyuan, XIA Yu, et al. Voiceprint recognition method based on SE-DR-Res2Block[J]. Chinese Journal of Engineering, 2023, 45(11): 1962-1969. [2] 李如玮, 潘冬梅, 张爽, 等. 基于Gammatone滤波器分解的HRTF和GMM的双耳声源定位算法[J]. 北京工业大学学报, 2018, 44(11): 1385-1390.doi:10.11936/bjutxb2017090015LI Ruwei, PAN Dongmei, ZHANG Shuang, et al. Binaural sound source localization algorithm based on HRTF and GMM under gammatone filter decomposition[J]. Journal of Beijing University of Technology, 2018, 44(11): 1385-1390.doi:10.11936/bjutxb2017090015 [3] 牛晓可, 黄伊鑫, 徐华兴, 等. 基于听皮层神经元感受野的强噪声环境下说话人识别[J]. 计算机应用, 2020, 40(10): 3034-3040.NIU Xiaoke, HUANG Yixin, XU Huaxing, et al. Speaker recognition in strong noise environment based on auditory cortical neuronal receptive field[J]. Journal of Computer Applications, 2020, 40(10): 3034-3040. [4] 许东星, 戴蓓蒨, 刘青松, 等. 基于超音段韵律特征和GMM-UBM的文本无关的说话人识别[J]. 中国科学技术大学学报, 2010, 40(2): 157-162.doi:10.3969/j.issn.0253-2778.2010.02.009XU Dongxing, DAI Beiqian, LIU Qingsong, et al. Text-independent speaker recognition based on super-segment prosodic feature and GMM-UBM[J]. Journal of University of Science and Technology of China, 2010, 40(2): 157-162.doi:10.3969/j.issn.0253-2778.2010.02.009 [5] 张庆芳, 赵鹤鸣, 龚呈卉. 基于因子分析和特征映射的耳语说话人识别[J]. 数据采集与处理, 2016, 31(2): 362-369.ZHANG Qingfang, ZHAO Heming, GONG Chenghui. Whispered speaker identification based on factor analysis and feature mapping[J]. Journal of Data Acquisition and Processing, 2016, 31(2): 362-369. [6] 王明合, 唐振民, 张二华. 基于I-Vector局部加权线性判别分析的说话人识别[J]. 仪器仪表学报, 2015, 36(12): 2842-2848.doi:10.3969/j.issn.0254-3087.2015.12.026WANG Minghe, TANG Zhenmin, ZHANG Erhua. I-Vector based speaker recognition using local weighted linear discriminant analysis[J]. Chinese Journal of Scientific Instrument, 2015, 36(12): 2842-2848.doi:10.3969/j.issn.0254-3087.2015.12.026 [7] 韩佳俊, 马志强, 王洪彬, 等. 基于I-Vector特征融合的蒙古语说话人特征提取方法[J]. 中文信息学报, 2023, 37(1): 71-78.doi:10.3969/j.issn.1003-0077.2023.01.007HAN Jiajun, MA Zhiqiang, WANG Hongbin, et al. A speaker feature extraction method based on I-Vector resource fusion[J]. Journal of Chinese Information Processing, 2023, 37(1): 71-78.doi:10.3969/j.issn.1003-0077.2023.01.007 [8] 刘晓璇, 季怡, 刘纯平. 基于LSTM神经网络的声纹识别[J]. 计算机科学, 2021, 48(增2): 270-274.LIU Xiaoxuan, JI Yi, LIU Chunping. Voiceprint recognition based on LSTM neural network[J]. Computer Science, 2021, 48(S2): 270-274. [9] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 770-778. [10] GAO S H, CHENG M M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652-662.doi:10.1109/TPAMI.2019.2938758 [11] 陈志高, 李鹏, 肖润秋, 等. 文本无关说话人识别的一种多尺度特征提取方法[J]. 电子与信息学报, 2021, 43(11): 3266-3271.doi:10.11999/JEIT200917CHEN Zhigao, LI Peng, XIAO Runqiu, et al. A multiscale feature extraction method for text-independent speaker recognition[J]. Journal of Electronics & Information Technology, 2021, 43(11): 3266-3271.doi:10.11999/JEIT200917 [12] YADAV S, RAI A. Frequency and temporal convolutional attention for text-independent speaker recognition[C]//ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona: IEEE, 2020: 6794-6798. [13] DAWALATABAD N, RAVANELLI M, GRONDIN F, et al. ECAPA-TDNN embeddings for speaker diarization[C]//Interspeech 2021. ISCA: [s.n.], 2021: 3560-3564. [14] DAI Y M, GIESEKE F, OEHMCKE S, et al. Attentional feature fusion[C]//2021 IEEE Winter Conference on Applications of Computer Vision (WACV). Waikoloa: IEEE, 2021: 3559-3568. [15] 邓力洪, 邓飞, 张葛祥, 等. 改进Res2Net的多尺度端到端说话人识别系统[J]. 计算机工程与应用, 2023, 59(24): 110-120.doi:10.3778/j.issn.1002-8331.2208-0085DENG Lihong, DENG Fei, ZHANG Gexiang, et al. Multi-scale end-to-end speaker recognition system based on improved Res2Net[J]. Computer Engineering and Applications, 2023, 59(24): 110-120.doi:10.3778/j.issn.1002-8331.2208-0085 [16] 李泽琛, 李恒超, 胡文帅, 等. 多尺度注意力学习的Faster R-CNN口罩人脸检测模型[J]. 江南娱乐网页版入口官网下载安装学报, 2021, 56(5): 1002-1010.doi:10.3969/j.issn.0258-2724.20210017LI Zechen, LI Hengchao, HU Wenshuai, et al. Masked face detection model based on multi-scale attention-driven faster R-CNN[J]. Journal of Southwest Jiaotong University, 2021, 56(5): 1002-1010.doi:10.3969/j.issn.0258-2724.20210017 [17] THEVAGUMARAN R, SIVANESWARAN T, KARUNARATHNE B. Enhanced feature aggregation for deep neural network based speaker embedding[C]// 2022 Moratuwa Engineering Research Conference (MERCon). Moratuwa: IEEE, 2022: 1-5. [18] 宋昕洋, 阎志远, 孙沐毅, 等. 说话人生成研究现状与发展趋势[J]. 计算机科学, 2023, 50(8): 68-78.doi:10.11896/jsjkx.221000031SONG Xinyang, YAN Zhiyuan, SUN Muyi, et al. Review of talking face generation[J]. Computer Science, 2023, 50(8): 68-78.doi:10.11896/jsjkx.221000031 -
 下载:
下载:







 点击查看大图
点击查看大图

计量
- 文章访问数:8
- HTML全文浏览量:7
- PDF下载量:1
- 被引次数:0